Apache Hbase —— 简介
1 简介

HBase 是以 Google 的 Bigtable 为模型的开源非关系型分布式数据库,提供了一种存储大量稀疏数据的容错方式,适用于需要低延迟随机访问和高达 PB 级的海量存储的用例。
HBase采用共享存储架构,将计算层与存储层分开,存储层通常位于HDFS(Hadoop分布式文件系统)上。这种架构选择实现了吸引人的功能,如平滑扩展和成本优化等。以下是一些用例,在这些用例中,HBase 可能是一个不错的候选者。
- 近乎实时的大规模分布式键值或表模式存储系统,数据量从 100 TerraBytes 到 100s PetaBytes 甚至更高
- 高吞吐量、写入密集型应用程序,可以容忍延迟波动,大约 100 毫秒
- 按行键顺序扫描是必需的读取模式
- 与Hadoop生态系统结合使用,如MapReduce、Spark、Flink、Hive、HDFS等
- 结构化、半结构化数据架构,可选择稀疏分布
一些具体用例包括:
- 电子商务订购系统。每日订单和用户操作可以存储在 HBase 中,实现对海量订单的低延迟随机访问。历史订单数据也可以存储在HBase中,通过MapReduce、Spark、Flink等计算框架运行离线分析作业
- 搜索引擎。网络链接的原始内容以及分析特征数据可以存储在 HBase 中,以计算搜索结果排名等
- 日志聚合和指标。例如,OpenTSDB(开放时序数据库)是一个专门用于日志聚合和指标收集的开源数据库系统
下面列出了 HBase 的一些功能:
- 批量加载。数据迁移等用例可能需要将大量数据导入 HBase。读出每一行数据,然后写入 HBase 效率低下,有时甚至不可行。HBase 提供批量负载,支持直接访问 HDFS 的数据,绕过 HBase 的大部分写入路径以提高效率
- 协处理器。HBase 支持通过协处理器框架围绕 HBase 函数执行用户定义的生命周期钩子函数,从而有机会扩展功能并允许细粒度定制
- 过滤器。HBase 允许用户将过滤逻辑定义为过滤对象,并将过滤过程向下推送到服务器端,以避免不必要的数据产生 RPC 成本
- MOB,中型对象存储侧重于优化大小介于 10 到 100 MB 之间的值
- 快照。在 HBase 中备份数据的方法之一,包括通过克隆现有快照来创建新表
- 复制。一个 HBase 集群中的数据可以通过同步更改历史记录(具体为预写日志)复制到另一个 HBase 集群
2 Hbase如何组织数据
HBase 中的表是半结构化的,这意味着必须在使用前定义列族。数据单元格由特定行键、特定列系列、确切的列限定符和时间戳(对于多版本单元格中的特定版本)唯一标识。数据稀疏地存储在 HBase 中,缺失的列根本不占用存储空间。
Hbase 支持多版本数据,这意味着“一个单元格”实际上由多个单元格组成,每个版本一个单元格,按时间戳降序排序。为了便于理解,可以粗略地将数据组织视为下面的 JSON 数组。
1 | // table name format:"${namespace}:${table}" |
- HBase Architecture HBase 架构
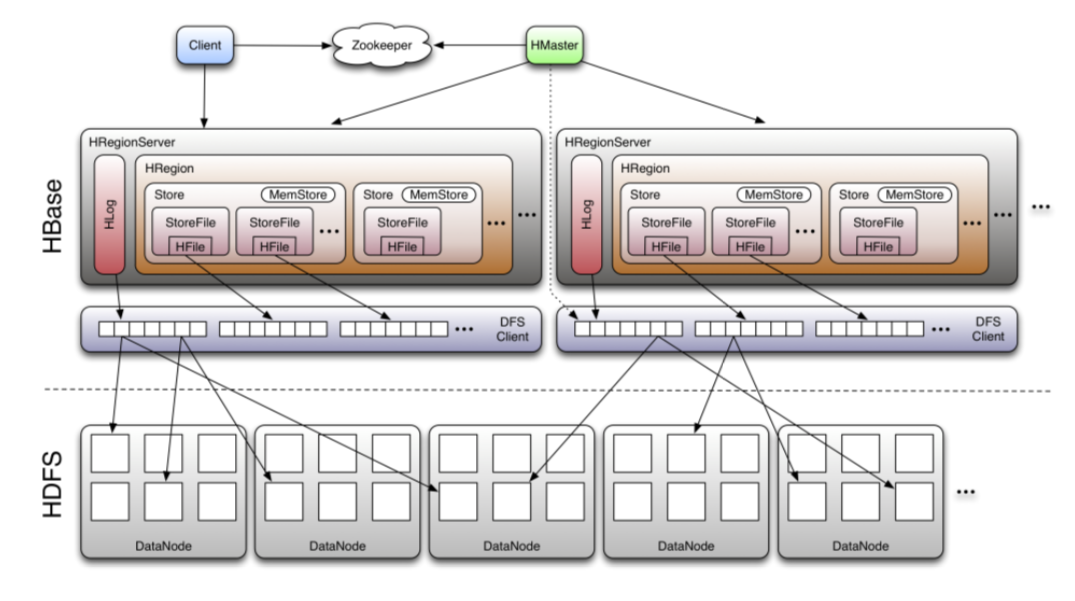
- Hbase 集群由以下组件组成
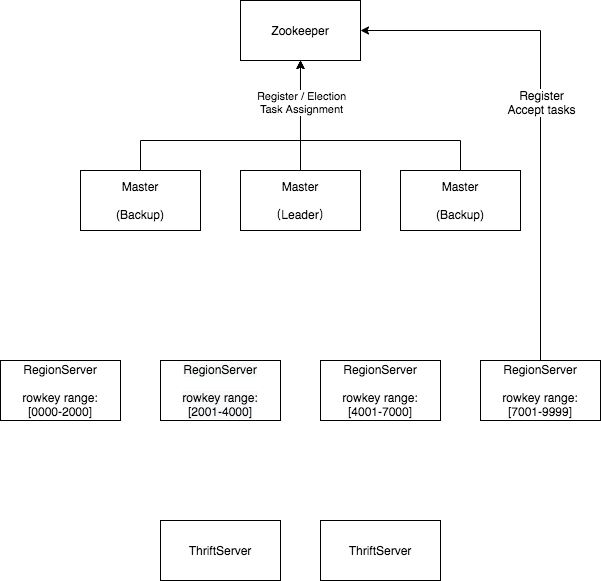
- Zookeeper。为了在分布式系统中达成共识,Zookeeper 用于 HBase 主领导选举、服务发现和分布式任务管理等。
- Master。HBase master 管理集群的元数据,并调度区域服务器,如存活检查、重新平衡等。只有 master 的 leader 实例负责,follower 实例处于备用状态,当 leader 关闭时通过 leader 选举接管,从而实现高可用。
- Region Server。每个Region Server实例都在不相交的连续行键范围内提供数据,并且所有Region Server一起覆盖整个行键空间。
- Thrift Server。HBase 还提供了一个 Thrift 协议来操作数据。Thrift 请求由 Thrift 服务器代理到Region Server。
3 HBase客户端如何执行读/写请求
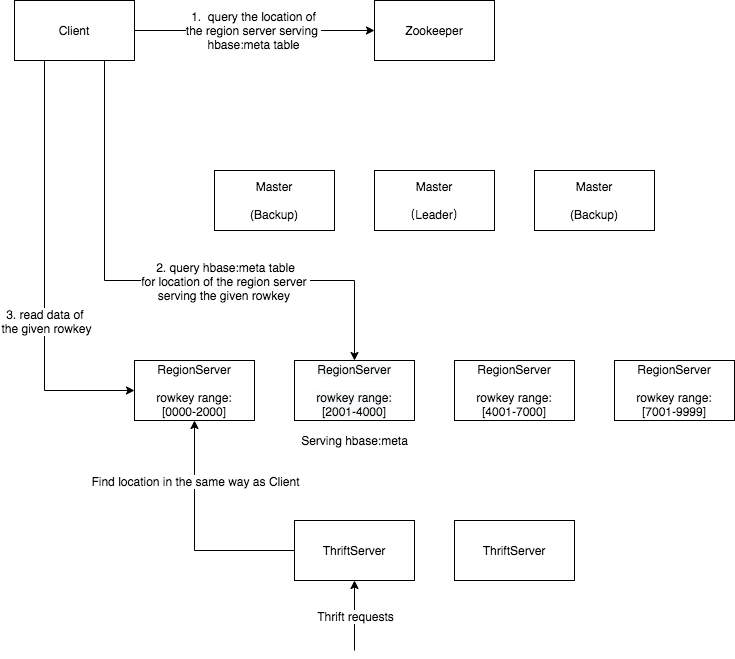
HBase 客户端配置了与目标 HBase 集群对应的 Zookeeper 信息
- 客户端请求 Zookeeper 查找Region Server A 提供元数据表 ‘hbase:meta’
- 然后,客户端请求区域服务器 A 在“hbase:meta”表中查找为目标行键提供服务的Region Server B
- 最后,客户端请求Region Server B 操作目标行键的数据
- 然后,位置信息将缓存在客户端中,以避免查找成本
4 当我们向 HBase 读取/写入数据时会发生什么?
HBase 实现了一种称为日志结构化合并树的数据结构。
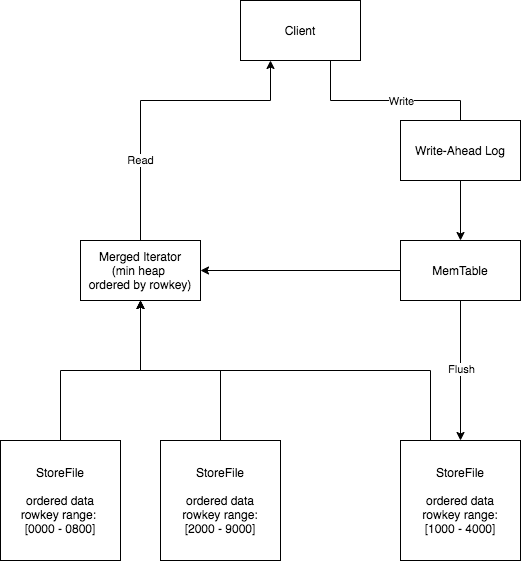
当收到写入请求时,更改记录首先记录在预写日志中,该日志是持久存储在磁盘上的仅追加日志。然后将数据写入 MemTable,这是一种内存中的数据结构,可使行保持顺序,并支持二进制搜索和行的正向和反向迭代,通常由 ConcurrentSkipListMap 实现。
一旦 MemTable 的大小达到配置的阈值,就会触发刷新,将 MemTable 数据写入存储在 HDFS 上的 StoreFiles 中。顺便说一下,每个列系列都有自己的 MemTable 和 StoreFiles。
既然一个列族的数据可以存储在 MemTable 中,也可以存储在一个区域服务器内的多个 StoreFile 中,那么我们如何读取一行呢?构造一个合并的迭代器,将所有 StoreFile 和 MemTable 组合在一起,形成一个全局有序的视图。首先,为每个 StoreFile/MemTable 创建一个迭代器,该迭代器可以在 StoreFile/MemTable 中按顺序迭代行。其次,在这些迭代器上构造一个最小堆,使用比较器作为迭代器的当前行。因此,可以确保最小堆顶部的迭代器中的当前行是全局顺序的下一行。
- HBase 中的预写日志
- ConcurrentSkipListMap 的结构